
Screen-friendly version of this page
The presentation of the problem set solutions, given during the contest.
Below, we present solution sketches for all the problems. They are by no means meant to be a comprehensive description, but you should be able to get the general idea in case you are stuck with any task.
In this task, you are to compute a distance between two segments in three dimensional space. Let P0 and P1 be the endpoints of the first segment and Q0 and Q1 be the endpoints of the second one. Start by finding linear functions P and Q, such that P(0) = P0, P(1) = P1, Q(0) = Q0, and Q(1) = Q1. We also use P and Q for denoting segments and use p and q for the corresponding vectors, i.e., p = P(1) - P(0) and q = Q(1) - Q(0).
First, we need a geometric primitives for computing the distance between a point A and a segment P. Observe that the distance is the minimum of the function d(P(x),A), where d is the distance between two points and x is from range [0,1]. Programming this primitive boils down to a simple function minimization. As a matter of fact, we may extend this approach to solve the actual problem: we have to find the minimum of d(P(x), Q(y)), where x and y are both from [0,1]. This can be also computed using calculus (slightly more involved than in the previous case).
Below we present more algebraic approach (whose advantage is that it works also in higher dimensions). First, we check whether the segments are parallel. If so, the task reduces to finding the points-to-segment distances and checking some boundary cases. Otherwise, for non-parallel segments, we will find the pair of the closest points P(x), Q(y), where x and y are arbitrary real numbers. We use the fact that the for non-parallel segments, these points are unique and segment (P(x),Q(y)) is perpendicular both to P and to Q. By writing this segment as a vector w = P(x) - Q(y), we obtain that w · p = 0 and w · q = 0. This gives us two equations with two variables, x and y. After having computed x and y, it is sufficient to check whether P(x) and Q(y) lie in segments P and Q (i.e., whether x and y belong to [0,1]) or outside of them. In the latter case, the distance is minimized at some endpoint.
Boundary of the upper (lower) gray region is called the upper (lower) envelope of a given set of lines. In the problem you are asked to find the distance between these two envelopes. Let's start with finding the envelopes themselves. As the situation is clearly symmetric, we can focus on finding the upper envelope, represented as a sequence of segments, with the leftmost and the rightmost segments half-infinite.
Start with transforming all equations into the form y=Ax+B, and observe that if one traverses the envelope from left to right, the encountered segments belong to lines with (strictly) increasing A coefficients. This suggest that we might try to sort the lines according to these coefficients and add them one-by-one, updating the current envelope. We start with the envelope of the first two lines computed naively. Then, adding a line whose A coefficient is larger than the coefficient of all already processed lines requires:
These steps are illustrated on the following picture.
Assuming the segments are kept in a left-to-right sorted list, all these operations can be performed in constant time. We only need a few geometric primitives: checking if a point lies on the right side of a line, and computing the intersection of two lines (which you probably have already prewritten).
Now the problem reduces to finding the distance between two sets of segments. It is not difficult to see that the smallest distance is achieved for a pair of points p,q such that either p or q is an endpoint of some segment. So, for each endpoint of the upper (lower) envelope segment we should find the closest point on the lower (upper) envelope. The envelopes can be thought of as convex polygons so you might use a generic distance-to-convex-polygon procedure. Here the situation is slightly less involved, though, and you can use a single binary search. Alternatively, you can observe that moving from left-to-right on one envelope results in moving the optimal point on the other one from left-to-right as well, and get a linear time for this part of the problem.
The total complexity is O(n log n) because we need to sort the lines according to their angles.
We are asked to find the longest subword of the form wwRwwR, or, in other words, the longest even palindrome composed of two smaller even palindromes. Knowing that we will look for an even palindromic subword, it makes sense to start with a succinct description of all such subwords. If the given word is s[1..n], we would like to calculate, for each i=1,2,...,n, the largest k, such that s[i]=s[i-1], s[i+1]=s[i-2], ..., s[i+k]=s[i-1-k]. We call this value of k=r(i) the palindromic radius at i. As you might already know, it is possible to compute all these values in linear time using the Manacher's algorithm. Do not worry if you have not, though: the time limits were set to allow a more direct O(n log n) procedure to pass: for each i do a binary search for the largest k; to check a single k, use hashing to verify the equality of the corresponding two fragments of s in constant time.
After computing all r(i), we are left with the following task: for each i=1,2,...,n compute the largest k ≤ r(i) such that there is j inside [i-k/2,i-1] for which j+r(j)≥ i. Number i corresponds to the center of a potential wwRwwR, and i-j is the length of w. This task can be solved with a single left-to-right sweep: we store all potential values of j ordered according to j+r(j) in a structure allowing fast inserts, removals, and successor queries. To process a given i, we first insert i-1 into the structure, then remove all j for which j+r(j)<i, and find the successor of i-k/2, if any. This successor corresponds to the longest possible w for the current i. Implementing the structure as a balanced search tree results in O(n log n) running time.
It turns out that it is possible to improve the running time using union-find data structure. We leave it as an interesting exercise for the reader.
Let A[1..n] be the given sequence. In the following, by a subsequence we mean a contiguous subsequence. First we perform some preprocessing, which can be done in linear time: for any i, we compute starting[i]: the length of the longest increasing (contiguous) subsequence starting at i and ending[i]: the length of the longest increasing subsequence ending at i.
Then, we sweep A from left to right. When we process entry A[i] = y, the potential solution we want to consider is the longest subsequence within A[1..i-1] ending at a value smaller than y (denoted best(y)) plus starting[i].
For computing best(y), we maintain a set M of pairs (x,len), sorted by the pairs' first elements. It can be implemented for example by a binary tree or STL set. A pair (x,len) means that the there exists an increasing subsequence (within the prefix of A processed so far) of length len ending with value x. For any x, we just store the length of the longest such subsequence.
Further, we observe that we do not have to remember all such pairs, as some of them are definitely better than the other. More specifically, if we have two pairs (x1, len1) and (x2, len2), where x1 ≤ x2 and len1 ≥ len2, then we say that pair (x2, len2) is dominated by pair (x2, len2). It does not make sense to store any dominated pair in set M. Therefore, we may assume that since pairs are sorted in the order of increasing values of x, then the corresponding lengths are increasing as well.
In the set M, the required pair can be found by binary search. Further, M can be updated as follows: while processing entry A[i], we try to insert pair p = (A[i], ending[i]) into M taking care of the following issues: (i) we do not insert p if it is dominated, and (ii) we purge all pairs from M that are dominated by p. Access to M can be performed in logarithmic time and all candidates for purging create contiguous subset of M, so their processing can be done in amortized constant time.
In total, the whole solution can be implemented in O(n log n) time.
We go through the forecast from left to right. For each rainfall over lake ti we must find a non-rainy day j with j<i, and order the dragon to drink from the lake ti on the j-th day. The question is which j should we choose if there are many possibilities. Well, it makes sense the choose j as small as possible. On the other hand, if we simply choose the smallest not-yet-used j, it might be incorrect: consider the sequence 0 0 1 0 1 0 1 2, the second 1 must be assigned a 0 occurring after the first 1. A better (and correct) idea is that we should choose j as small as possible, but occurring after the previous occurrence of ti, if any.
To implement this solution we need a structure to perform two types of operations: inserting a number, and finding successor. STL's set is enough for that, resulting in O(n log n) running time. It is also possible to use union-find here and get a slightly better running time of O(n log* n).
The process of adding fields to make the parcel final by iterating steps 1-3 will be called finding the strange hull of a given initial set of fields. The problem requires you to count the subsets of the initial fields having the same strange hull, which suggests that we should begin with finding its efficient characterization.
First, note that if x coordinates of all initial fields are between xmin and xmax, so are the coordinates of all fields in the hull. In other words, if there are no initial fields with centers on some side of a x=a line, there are no such fields in the hull as well. The same applies to any line y=a, y=x+a, y=-x+a (but fails to be true for other lines!). We claim that in fact this is a characterization of all fields of the strange hull: it contains all fields, such that there is no line of the form x=a, y=a, y=x+a, y=-x+a such that all initial points are on the other side. In other words, after calculating the minimum and maximum values of x, y, x-y, x+y for all initial fields (x,y), the hull contains all fields (x,y), such that adding (x,y) does not change those minimum and maximum values. Hence, its boundary consists of at most 8 segments as shown on the picture:

Consider the situation on two neighbouring segments of the boundary: say that (x0,y0) lies on the segment corresponding to y=y0, and (x1,y1) on the segment corresponding to y=x+y1-x1. If (x0,y0) is not on the y=x+y1-x1 as well, y=x+y0-x0 is above (x1,y1). Hence the segment connecting (x0,y0) and (x1,y1) intersects the inner part of (x0+1,y0), see picture:
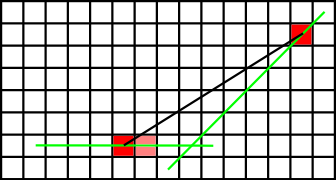
By iterating the same argument again and again, we get (x0,y0) placed on y=x+y1-x1, then the segment intersects all fields between (x0,y0) and (x1,y1). Having the boundary, it is easy to see that all fields inside are in the strange hull as well.
So far, so good. But we still haven't solved the original problem! But now we know that all subsets with the same minimum and maximum values of x, y, x-y and x+y should be counted. This can be seen as the following question: given n bitmasks of size 8, count the subsets with the bitwise OR equal to 11111111. This can be solved in a straightforward manner, using the inclusion-exclusion principle.
Checking who won the tic-tac-toe was the simplest task in this problem set. Yes, no catch here, just a couple of if-then-else constructs.
The problem requires developing a data structure for storing a set S of 2D points and performing a few operations. To simplify the solution, we transform the problem as follows: S initially contains all points given in the input, each of them colored red. Then, we need to perform a few operations efficiently:
Then, we are able to solve the original problem: for each point given in the input, we first check if it belongs to S. If not, we output FAIL, otherwise we change its color to green, then enumerate and remove all points contained in its region. Note that each point will be enumerated (and removed) at most once, so if we can enumerate in O(k log n), where k is the number of points inside the region, and erase a single point in O(log n), the whole running time will be just O(n log n).
Thus, in fact, the main difficulty is how to design a structure for enumerating points contained in a region. Lets focus on the case of a=1 first. To make things simpler, rotate the plane by 135 degrees. Then the question reduces to enumerating points dominated by a given (x0,y0), which is a fairly well-known task (you can use priority search tree to get O(k+logn) here). But we still have to cope with a=2 somehow. Fortunately, it is not that different from a=1: we can rotate and stretch the plane so that the region we are interested in becomes a rectangle! In other words, there is a linear transformation which reduces the problem to dominance queries as well. An idea of such a transformation is depicted below.
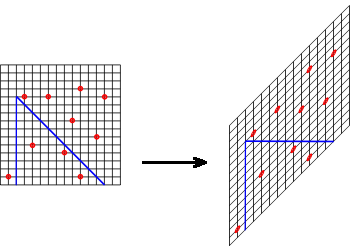
The only remaining problem is that we can have a few points with a=1, and a few with a=2, and the transformations for those two cases are clearly different. To deal with this difficulty we build two separate structures S(1) and S(2). Both of them contain all points from the input in the very beginning, and S(a) allows us to quickly enumerate points contained in a region bounded by y=a(x-x0)+y0 and y=-a(x-x0)+y0. If during the enumeration we take care to erase points from both structures, the total running time will be O(n log n).
Below is the alternative solution kindly pointed to us by Professor Danny Sleator.
There's an O(n log^2 n) algorithm that uses the standard set API. (As opposed to the O(n log n) algorithm that uses a customized 2-d query range-query data structure.) This is explained below.
We keep two set data structures (ordered by x-coordinate). The wide and the narrow. The algorithm takes three passes over the input data. In pass 1, we insert the points one by one into the wide or narrow data structure (and it's a FAIL point if it's below the profile of either the wide or narrow). And as a by-product of pass 1, we keep two arrays of versions of the wide and narrow profile sets, indexed by time. (Note here I am exploiting the persistence of data structures in this functional language.) For each point I also generate a kill list of points (of the same wideness - so far) that that point causes to be deleted.
So far, we have not accounted for wide points that are obscured by future narrow ones, and vice versa. So in the 2nd pass, we process the points in time order (again) and for each wide one we do a binary search on the array of narrow profiles, and vice versa. This gives the earliest point of the other wideness that (if it exists) dominates this point. This search is O(log^2 n). We add the point being processed to the kill list of the point that causes it to die.
In the 3rd pass we again process the non-FAIL points in time order. In this case we also keep a set S of visible points at all times. When a point p is processed we insert it into S. Then we remove all the points on p's kill list from S. (It might try to remove a point twice, once from a wide kill list once from a narrow, but this is irrelevant.) At each point in time the size of S is the value we need to output.
Given a well-bracketed word w[1..n], your task is to find the lexicographically next well-bracketed word. One type of brackets is created by letters a and e, another one by letters i and o. We describe a solution on an example: let w = aaioee. We try to find to find the lexicographically first well-bracketed word starting with the following prefix:
We stop sweeping these prefixes when we succeed to find such word. The word sets described by these prefixes cover all words which are lexicographically later than w.
But how to find a well-bracketed word starting with a given prefix of length k? First, we compute the brackets' imbalance after reading such prefix, i.e., we put a and i on stack when we read them and we pop them from stack, when we read e and o, respectively. Let f be the number of stack elements after reading the prefix.
Then, we check whether using the remaining n-k places we can balance f brackets that are already on stack. If f > n-k, then it is not possible. Otherwise, it is possible, and the lexicographically smallest word consists of the prefix, followed by the (possibly empty) string a(n-k-f)/2 e(n-k-f)/2, and finally a sequence of f characters which balances the stack.
As we can compute the stack contents for each prefix in the incremental way, the total runtime is O(n).
You have to construct a bipartite graph, whose each part has at most 200 nodes and the number of perfect matchings is at exactly n. Nodes of the first part are called knights and nodes of the second one are called horses.
We show how to construct such a graph Gn with n perfect matchings and an additional property: it has two distinguished nodes, one knight and one horse, and if they are both removed from the graph, then it has exactly one perfect matching. Constructing G1 is easy (K and H are distinguished nodes).
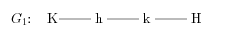
Now it remains to show how — on the basis of Gn — to construct graphs Gn+1 and G2n. K and H denote the distinguished nodes in Gn, whereas K' and H' in the newly constructed graph (Gn+1 or G2n, respectively).
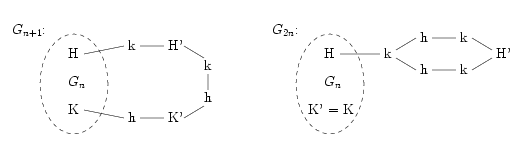
Checking that these graphs indeed satisfy the given condition is left as an easy exercise. The solution is obtained by iteratively applying these constructions.
Below is the alternative solution kindly pointed to us by Professor Danny Sleator.
Just messing around with counting matchings, I tried this kind of graph, where each node i on the left is connected to i and i+1 and i-1 on the right. (We ignore out of bounds indices, so every node connects to 3 except the ones on the top and the bottom.) It's easy to prove by induction that this gives the Fibonacci numbers.
This leads to the idea considering what happens if you take a graph G, and add two more nodes to it. Add the two nodes on the top and connect them together, and also to the two top nodes of G. The number of matchings is a + b, where a is the number of matchings of G, and b is the number of matchings in G when the top two nodes are deleted (or matched to something else).
So let's denote by [a,b] a graph that has a matchings and if you remove the two top nodes it has b matchings. Define the operator A to mean adding a new connected pair to the top of the graph. Then A[a,b] = [a+b,a].
On the other hand, suppose we added a pair of nodes to the top of [a,b] (connected to the two top nodes of the graph) that were not connected to each other. Call this operator B. Then B[a,b] = [b,a].
Let's start with a single edge, [1,1]. Let's see what we can get. By applying A repeatedly we get [2,1], [3,2], [5,3], etc. Fibonacci numbers. But if we throw in some B operators we can, it turns out, get anything we want.
To get any desired number, we need to reverse this process. Say we
want to get [n,a] for n>a. Well if we could get [a,n-a] then we can
apply A to it A[a,n-a] = [n,a]. How do we get [a,n-a]? Well, if a >
n-a, then we can do A inverse again. So A[n-a,2a-n] = [a,n-a]. If
a
Other than being relatively prime to n, how do we pick a? If we pick
a=1 then this process will be too slow (takes n-1 steps). So we want
an a that works fast. Pick a close to n/1.618..., then the first few
steps make huge progress (no swaps are necessary for a while).
So my program just tests a few numbers near n/1.618 and finds the
choice of a that leads to the smallest number of steps to [1,1]. The
number of iterations (nodes on a side) is usually quite close to log n
(base 1.618). The resulting matrix is tri-diagonal.
You can find some additional
sketches of the solutions and ideas (in Polish) at the webpage of informal post-CERC contest.
Informal post-CERC'10 contest